# Configuration (Advanced)
Source: https://docs.charlielabs.ai/config-advanced
Repository-level config schema, instruction files Charlie reads, environment variables, and CI tips.
## Overview
This page describes repository‑level configuration, instruction files that Charlie reads, and environment variables used during runs.
This guide covers three knobs you control per repository:
* `.charlie/config.yml` – feature flags and run/verify commands
* Project “rules” and instructions – Markdown files Charlie reads for context
* Per‑repo environment variables – injected into Charlie’s ephemeral VM (Devbox)
## 1) Repository config: `.charlie/config.yml`
Location: `.charlie/config.yml` on the default branch. Changes take effect after merging to the default branch. If the file is missing or invalid, safe defaults are used.
Schema and behavior:
* `ignorePatterns: string[]` – Glob patterns to exclude from extended diffs and context gathering. Useful for generated code, vendored assets, or giant lockfiles.
* `checkCommands: { fix?, lint?, types?, test? }` – Shell commands Charlie can run inside the Devbox.
* `checkCommands: { fix?, lint?, types?, test? }` – Shell commands Charlie can run inside the Devbox.
* All commands run from the repository root inside the Devbox.
* `fix` is run after Charlie edits code (format/lint autofix, codegen, etc.).
* `types` enables a TypeScript verification step when provided.
* `lint` runs your linters (for example, ESLint).
* `test` runs your unit tests (not E2E or integration tests).
* `lint` and `test` are only enforced when `beta.forceAllCheckCommands` is `true`.
* `beta` – Experimental feature toggles:
* `automaticallyReviewPullRequests` (default: true) – Auto‑request a review from Charlie when a PR is opened or marked ready for review.
* `skipEmptyReviews` (default: false) – If the generated review has no significant findings, skip posting entirely.
* `filterReviewComments` (default: false) – Classify and post only helpful/actionable comments.
* `canApprovePullRequests` (default: false) – Allow Charlie to post an “Approve” review when appropriate (never for Charlie-authored PRs).
* `forceAllCheckCommands` (default: false) – When true, treat `lint` and `test` in `checkCommands` as required verifiers.
Example:
```yml
ignorePatterns:
- '**/*.lock'
- '**/dist/**'
- '**/generated/**'
checkCommands:
fix: bun run fix
lint: bun run lint
types: bun run typecheck
test: bun run test
beta:
automaticallyReviewPullRequests: true
skipEmptyReviews: true
filterReviewComments: true
canApprovePullRequests: false
forceAllCheckCommands: false
```
Notes:
* Invalid or misshaped values are ignored per‑field and replaced with defaults (other valid keys are preserved).
* `ignorePatterns` affect Charlie’s extended diff during reviews; large or noisy files listed there won’t drive comments.
## 2) Project instructions (“rules” files Charlie reads)
Charlie scans a small, well‑known set of instruction files from your repo and includes them in its working context. Use these files to teach Charlie repo‑specific conventions, pitfalls, naming, architecture guidelines, and common mistakes to avoid. Keep them short, concrete, and evolving.
Recognized files and scope:
* `.charlie/instructions/*.md` – Global to the entire repo.
* `CLAUDE.md` – Scoped to its directory and all descendants.
* Example: `services/db/CLAUDE.md` applies to `services/db/**`.
* `AGENTS.md` – Scoped to its directory and all descendants.
* Example: `apps/api/AGENTS.md` applies to `apps/api/**`.
* `.cursor/rules/*.mdc` – Modern Cursor rules; scope is the directory that contains the `.cursor/rules` folder.
* Example: `apps/web/.cursor/rules/auth.mdc` applies to `apps/web/**`.
* `.cursorrules` (repo root legacy) – Global to the entire repo.
Writing effective rules:
* Prefer imperative, testable directives over philosophy. Show tiny code snippets when helpful.
* Capture recurring review feedback, gotchas, naming/typing rules, file layout, and internal API contracts.
* Update continuously as patterns solidify; the goal is to prevent repeat mistakes.
## 3) Environment variables (Dashboard → Manage → Repository)
Add per‑repository environment variables in the dashboard. Charlie injects these into each ephemeral Devbox so Charlie can build, run tests, and start dev tools like a teammate on your machine.
What’s already provided when integrations are connected:
* `GH_TOKEN` – Installation access token for the repo (always set by Charlie).
* `LINEAR_API_KEY` – When Linear is connected.
* `SENTRY_AUTH_TOKEN` and `SENTRY_ORG` – When Sentry is connected.
Common variables you might add:
* `NPM_TOKEN` (or `NPM_AUTH_TOKEN`) – Private registry access; also enables installing internal CLIs in the Devbox.
* Remote cache or CI tokens used by your build (e.g., `TURBO_TOKEN`/`TURBO_TEAM` if you use Turborepo remote caching).
* E2E/dev server knobs (e.g., `PLAYWRIGHT_*`, `CYPRESS_*`, framework‑specific `NEXT_PUBLIC_*`, `VITE_*`).
* Service creds needed for non‑production runs (SDK read‑only keys, mock service URLs, etc.).
Guidance:
* Prefer non‑production, least‑privilege tokens. The Devbox is ephemeral and torn down after the run.
* If your repo uses Git submodules or private secondary registries, include any extra tokens those tools require.
CI tips:
* GitHub Actions: asking Charlie to “fix the build” lets Charlie fetch logs automatically with the GitHub CLI.
* Other CI (e.g., CircleCI): paste the failure snippet into the PR/Slack thread and ask Charlie to fix it; ensure any CI‑only env vars are added in the dashboard so tests can run in the Devbox.
Values are encrypted at rest and hidden in the dashboard after you save them.
## Quick FAQs
### “We merged config changes but nothing changed.”
Config is read from the default branch; ensure the file lives at `.charlie/config.yml` and changes are merged to default.
### “Charlie approved a PR.”
That only happens if `beta.canApprovePullRequests` is true, the review found no significant issues, and the PR isn’t authored by Charlie.
### “Lint/tests weren’t enforced.”
Provide the commands in `checkCommands` and set `beta.forceAllCheckCommands: true` to require `lint` and `test`.
For minimum setup steps, see the Setup guide.
# Docs, but Faster
Source: https://docs.charlielabs.ai/docs-but-faster
These are the fastest ways to learn about Charlie:
If your organization has Charlie installed, ask @CharlieHelps in GitHub or ask @charlie in a connected Slack/Linear instance.
Use the AI-enabled search bar at the top of this docs site.
Paste this LLM‑friendly reference into your model of choice: (click here).
# Extras: FAQ and Tips & Tricks
Source: https://docs.charlielabs.ai/extras
LLM-friendly FAQ and tips that complement Setup, How it works, and Configuration.
## Overview and usage
This page provides a compact, LLM‑friendly reference for common questions and practical guidance. Entries are concise, uniquely titled, and self‑contained.
For setup and core behavior, see:
* [Initial setup & installation](/setup)
* [How Charlie works](/how-it-works)
* [Configuration & advanced setup](/config-advanced)
***
## FAQ
### Does Charlie persist state between messages or threads?
* No persistent VM across events: each message or event starts a fresh, ephemeral environment (a new “run”).
* Continuity is achieved by using deterministic branch names and by re‑reading the prior thread: on a new message, Charlie clones the repo, checks out the deterministic branch, pulls from remote, and reads the Slack thread context to infer prior decisions. This can make it feel like the VM persisted even though it did not.
* Tip: explicitly name or pin the branch you want and keep using the same thread to reduce branch drift. See Tips & Tricks → Branch control.
### Can Charlie process images or screenshots in Slack or PRs?
* Yes. Charlie parses screenshots/images in GitHub PR/issue comments and in connected Slack/Linear threads. Add a short caption or highlight the relevant area for best results.
### How does Charlie decide what to review or comment on in PRs?
* Reviews are intentionally non‑agentic: Charlie gathers a bounded, deterministic context (diff, nearby files, comments, your rules) and reviews that. Charlie does not deep‑crawl the whole repo during the review itself. When information is missing, Charlie may use “if X isn’t handled elsewhere…” style caveats.
* To make reviews crisper, provide intent in the PR description and link to related files/decisions. See Tips & Tricks → Writing PRs Charlie reviews well.
### Will Charlie automatically run tests, lint, and formatting before committing?
* Tests/lint: Charlie typically runs tests and lint locally during a run when asked.
* Formatting: “Format before commit” helps avoid CI failures from minor nits (e.g., newline/end‑of‑file). Treat this as a requested improvement, not guaranteed behavior. Workarounds are listed under Tips & Tricks → Pre‑commit hygiene.
### How can Charlie help with CI failures and test logs?
* GitHub Actions: Ask Charlie to “fix the build”; Charlie can use the GitHub CLI to pull logs and iterate.
* Other CI (e.g., CircleCI): Provide the failing job’s error text or a machine‑readable results file in the PR/Slack thread and ask Charlie to fix it.
* Noise control: If auto‑reacting to webhooks feels noisy, keep the loop manual (ask Charlie to check CI on request) or add simple backoff rules.
### Can Charlie access Sentry or other observability tools?
* Sentry: Yes—connect Sentry via a token and then ask Charlie to query incidents and propose fixes. Use the dashboard to provide auth; then ask in Slack/PRs to “check Sentry for this error.”
* Other providers: Paste relevant logs or expose machine‑readable outputs Charlie can ingest.
### Where should we put rules/instructions so Charlie follows org‑specific conventions?
* Charlie reads common agent instruction files (e.g., rules used by Cursor/Claude/OpenAI) and project docs kept alongside code. You can place rules in the repo root and in specific subdirectories; Charlie will find and use them.
* Good patterns: directory‑scoped rules for tricky systems (e.g., Hasura triggers), and a simple glossary for team‑specific terms that lives in your Charlie instructions (for example, under `.charlie/instructions/`).
* See [Configuration & advanced setup](/config-advanced) for how repository‑local instructions interact with `.charlie/config.yml`.
### Does Charlie remember long Slack threads well?
* Long threads can degrade performance. Effective workaround today: ask Charlie to summarize the important parts, start a fresh thread with that summary, and continue there.
* Improvements to context handling are being explored; rely on How it works for current limits.
### How should we provide environment variables or special setup so tests run for Charlie?
* Use the dashboard to add repository environment variables that Charlie can read during runs. Only add non‑sensitive values appropriate for CI‑like use.
* If your repo needs conditional steps when Charlie is running, use a custom variable (for example, `CHARLIE=1`) in your scripts. See [Configuration & advanced setup](/config-advanced).
### Can we combine or migrate context between two separate Charlie threads?
* For complex workstreams, a practical approach is to ask Charlie to summarize each thread and then start a new thread with those summaries included.
***
## Tips & Tricks
### Repository hygiene
* Run Knip regularly to prune unused files, exports, and dependencies. Add a script (for example, `knip`) and treat warnings as actionable; keeping references clean improves navigation and reduces false positives in reviews.
* Configure GitHub Autolinks in Repository settings → Autolink references so issue keys like `TEAM-123` and ticket IDs in commit messages/PRs become clickable. This keeps discussion and history connected across tools.
### Writing PRs Charlie reviews well
* State intent upfront in the PR description (especially for pure refactors, framework upgrades, or JS→TS conversions) so comments stay concrete.
* Link relevant files/decisions. If code depends on config/metadata (e.g., Hasura), point Charlie to where that lives in the repo.
* Screenshots/images are supported. Include a brief caption and, when relevant, link to code paths so suggestions stay concrete.
### Rules and glossary placement that actually help
* Put instruction files close to the code they guide. Directory‑scoped rules help teach Charlie about event pipelines and trigger wiring.
* Maintain a lightweight glossary (“this term means X in your codebase”) to reduce repeated explanations.
* Cross‑check with [Configuration & advanced setup](/config-advanced) to understand how local instructions complement `.charlie/config.yml`.
### Branch control in Slack‑driven work
* Be explicit about the branch: “Use branch X for this thread.” Because each message starts fresh, clarity reduces accidental new branches.
* If Charlie commits to the wrong branch, say so directly and restate the target branch; Charlie re‑reads the thread and will correct course.
### Task batching to reduce CI churn
* When acknowledging multiple inline review comments (e.g., “yes” to three suggestions), ask Charlie to collect them and push a single commit to avoid multiple CI runs. Today this is best‑effort if you ask explicitly.
### Pre‑commit hygiene while formatting isn’t automatic
* Ask Charlie to run your repo’s formatter/linter before pushing: e.g., “run lint and format, then commit.” This avoids CI failures from trivial nits.
* If CI uses non‑default formatters (e.g., Biome), mention them by name in your instruction so Charlie invokes the right script.
### Working with CI beyond GitHub Actions
* CircleCI and others: paste failing error output (or attach machine‑readable test reports) and ask Charlie to fix tests. Providing artifacts helps.
* Rate/loop control: If you invite Charlie to auto‑respond to CI webhooks, consider a simple backoff (e.g., “stop after 4 failed tries and wait for a human”). Treat this as a preference pattern, not a built‑in limit.
### Managing long conversations
* When a Slack thread grows long (hundreds of messages), ask Charlie to summarize decisions, open a new thread with that summary, and continue from there. This keeps context sharp.
### Surfacing logs and observability
* Sentry: after connecting with a token via the dashboard, ask “Check Sentry for this error and propose a fix” to have Charlie cross‑reference source and open a PR.
* Other providers (Better Stack, CloudWatch): until native integrations exist, paste relevant log excerpts or link artifacts; Charlie can reason over the content.
### Handling complex event wiring (Hasura, webhooks, etc.)
* If behavior depends on metadata/config files (e.g., Hasura YAML), point Charlie at the exact paths and add directory‑local rules that explain the trigger flow. This dramatically improves search/navigation inside the repo.
### Asking for tests and local validation
* Ask Charlie to generate or update tests and to include local run output in replies. If a PR lacks tests, ask for them explicitly and request the local test output snippet.
### When two threads converge
* If work diverged across two Slack threads, ask Charlie to summarize each thread, then start a clean thread with both summaries and an explicit goal. This is the most reliable way to “merge contexts” today.
***
## Troubleshooting patterns
### “It says ‘build passed locally’ but my build fails”
* Environments may differ (missing env vars, browser dependencies, DB). Provide required env vars via the dashboard and mention any special setup. Ask Charlie to re‑run tests after injecting env.
### “Charlie fixed some Dependabot alerts but not all”
* Tell Charlie explicitly how many remain or list them; if needed, iterate with “keep going until all N are fixed.”
### “Too many branches were created”
* Restate the single authoritative branch for the thread and ask Charlie to consolidate changes there. If a “*PR for class of errors*” is desired, say so (e.g., “open a separate PR to fix the stacked errors”).
### “CircleCI logs are painful to copy over”
* Instead of copying UI text, attach the job’s machine‑readable results (e.g., Playwright JSON) to the PR or paste the raw failure block; then ask Charlie to fix the failing cases.
***
For current product behavior and configuration details, see [Initial setup & installation](/setup), [How Charlie works](/how-it-works), and [Configuration & advanced setup](/config-advanced).
***
## Scenario tips
### Code Reviews
* Mark PRs “Ready for review” or request a review from `@CharlieHelps` to trigger a review.
* State intent in the PR description (e.g., “pure refactor,” “framework upgrade”) and link any related files or prior decisions.
* Ask for focus (“limit feedback to correctness and TypeScript types”) or for a targeted pass (“only flag potential regressions in auth”).
### Technical Discussions
* Ask Charlie to explain modules or flows and to cite files/lines in the answer.
* Use “summarize this thread, then propose options with trade‑offs” to reach decisions faster.
* When searching for docs or patterns, name the feature and preferred locations (“look for rate‑limit docs in `docs/` and `src/middleware/`”).
### Code Contributions
* Be explicit about scope, branch, and acceptance criteria (“open a PR on `feat/payments-v2` that adds tests for X; all tests must pass”).
* Ask Charlie to run formatter/linter/tests before pushing and to include the local output in the reply.
* If changes span packages, request a single commit or a single PR unless you ask for a split.
### Linear Integration
* Link the GitHub repository to the correct Linear team first; then ask “create a PR from TEAM-123.”
* Specify branch naming and PR title conventions if you have them; Charlie will follow your guidance.
* Ask for bi‑directional context (“include key details from this Linear issue in the PR description”).
### Slack Integration
* Pin the working branch at the start of a thread and keep all follow‑ups in that thread.
* Use Slack for quick iterations; when the change is ready for full review, request a GitHub review from `@CharlieHelps` on the PR.
* For long threads, ask for a summary and continue in a new thread with that summary to keep context sharp.
* Ask @Charlie to create a well‑written Linear or GitHub issue from the Slack thread; Charlie will pull relevant context and draft it for you.
### If you’re not sure @Charlie understands or is correct
Ask @Charlie probing questions that require evidence and verification. Ask @Charlie to explain reasoning back before acting. This turns a guess into a check.
* Ask @Charlie to restate your request and the expected outcome in their own words (confirmation of understanding)
* Ask for concrete evidence: cite specific files, line ranges, commits, or config/instruction files relied upon (for example, `.charlie/config.yml`, rules under `.charlie/instructions/`)
* Ask to list assumptions, unknowns, and what additional info would change the answer
* Ask for a step‑by‑step reasoning outline or plan, and what alternatives were considered and rejected
* Ask for a minimal test, reproduction, or quick validation step, with expected vs. actual results
* Ask to surface relevant command output or logs (when applicable) from the run/devbox, or to point to existing CI logs referenced
* Ask to annotate where a suggested change applies in the diff (file + line) and why
* Ask for a brief comparison of two options with tradeoffs and a recommendation
* Ask for a confidence level and what would increase it
# How It Works
Source: https://docs.charlielabs.ai/how-it-works
Triggers, run lifecycle, capabilities, and constraints—with diagrams. Optimized for LLMs.
## Overview
This page explains how Charlie reacts to events, what happens during a run, what Charlie can do, and the key constraints.
### Key terms
* Run: a single, short‑lived execution created by an incoming event (e.g., PR opened, review requested).
* Devbox: an ephemeral VM Charlie starts for a run to check out code, install dependencies, run commands, and make changes.
## What triggers Charlie
Charlie listens for events from the tools you connect:
* GitHub (required)
* Pull request opened or marked “Ready for review”
* New commits pushed to an open pull request
* Review requested for `@CharlieHelps` or a comment mentioning `@CharlieHelps`
* PR review posted (human feedback on Charlie’s PR)
* Slack
* Messages that mention @Charlie in a channel or thread where the app is installed
* Linear
* Issues from teams linked to a repo
If Slack or Linear aren’t connected, those triggers simply don’t fire—GitHub alone is enough to get value.
## What happens during a run
Each event creates an isolated “run.” A run is single‑purpose and short‑lived. It cannot be paused or canceled once it starts.
1. Gather context
* Reads only what is needed from the triggering platform(s): PR diffs, relevant files, comments, labels, assignees.
* Loads the repository’s `.charlie/config.yml` and any project instructions that exist.
* Pulls linked context from Slack/Linear/Sentry when relevant and connected.
2. Start an ephemeral compute environment
* Spins up a fresh, temporary VM (“devbox”) with the repository checked out.
* Installs dependencies as needed and can run your optional `checkCommands` (e.g., lint, tests, typecheck).
3. Think and act
* Plans steps based on the event (review a PR, answer a question, make a change).
* Executes changes inside the devbox when edits are needed.
* Writes results back to the correct surface (GitHub, Slack, Linear).
4. Tear down
* Shuts down the devbox. No internal state from the run is kept.
### Visual overview
Triggers → Run starts → Gather context → Start ephemeral devbox → Execute plan → Post results → End run
## What Charlie can do
* Review pull requests (inline comments and summaries)
* Open pull requests and branches for fixes or refactors
* Push commits to existing PR branches (e.g., apply suggestions, fix build/lint)
* Comment and answer questions in GitHub, Slack, and Linear
* Create and update issues on GitHub or Linear
Everything Charlie does is visible where it happens: in the PR, the issue, or the Slack/Linear thread.
## Important constraints
* No cancellation: once a run starts, it runs to completion.
* No hidden state: Charlie does not retain state between runs beyond what is posted to GitHub/Slack/Linear (and the commits/PRs Charlie creates).
* Principle of least access: Charlie only reads data needed to fulfill the current run and only in the tools that are connected.
* Ephemeral compute: every run uses a fresh devbox and is torn down afterward.
## Usage tips
* Make events explicit
* Mark PRs “Ready for review” when you want feedback.
* Request a review from `@CharlieHelps` or mention `@CharlieHelps` in a PR comment to ask for help.
* In Slack/Linear, mention Charlie directly and provide quick context (“check failing tests in module X”). If the thread is long, ask for a brief summary first and then state the task.
* Be explicit about the action
* Say what you want: “open a PR”, “leave a comment diagnosing this”, “push a commit that…”.
* Include concrete context
* Reference files, functions, packages, or lines when asking for a change.
* State constraints
* Call out musts/must‑nots (e.g., “handle nulls; do not mutate global state”).
* Keep repo guidance close to code
* Add `.charlie/config.yml` for optional checks and preferences.
* Add project instructions under `.charlie/instructions/` to steer responses.
* Let runs finish
* Because runs can’t be canceled, start them when the PR or question is ready.
### Build/test feedback
* GitHub Actions: Charlie can fetch logs via the GitHub CLI when asked to “fix the build.”
* Other CI (e.g., CircleCI): paste the failing job’s error snippet into the PR or Slack thread and ask Charlie to fix it; add any missing env vars in the dashboard so tests can run in the devbox.
### Example PR review flow
```mermaid
sequenceDiagram
participant Dev as Developer
participant GH as GitHub
participant Charlie as Charlie
Dev->>GH: Open PR or mark ready for review
GH-->>Charlie: Event delivered (PR ready)
Charlie->>Charlie: Gather context + start devbox
Charlie->>GH: Post review comments + summary
Dev->>GH: Push follow‑up commits
Dev->>GH: Request review from @CharlieHelps
GH-->>Charlie: Event delivered (PR review request)
Charlie->>GH: Update with new findings or push fixes (if asked)
```
### Common prompts
* `@CharlieHelps review this PR`
* `@CharlieHelps open a PR to add tests for edge cases in `
* `@CharlieHelps leave a comment diagnosing this failure`
* `@CharlieHelps fix the failing tests in `
* `@CharlieHelps create a PR from LINEAR-123`
* `@CharlieHelps check GitHub Actions logs for this run and suggest a fix`
Open‑source repositories are supported. See Open Source for the exact invocation rules.
# GitHub Integration
Source: https://docs.charlielabs.ai/integrations/github
Connect GitHub so Charlie can review PRs, open PRs, and keep Linear and Slack in sync.
Connecting GitHub is required for Charlie to operate. This core integration gives Charlie access to your codebase and development workflow—enabling him to review code, push commits, create pull requests, and collaborate in your repository just like a fellow developer.
## What Charlie can do
With GitHub connected, Charlie works directly in your repositories and pull requests:
* **Review and improve code changes.** Charlie automatically reviews pull requests (especially when they’re marked “Ready for Review”) and provides detailed feedback. Mention `@CharlieHelps, review this PR` or assign him the pull request — he will analyze the diff and comment with findings on potential bugs, performance issues, and best practices.
* **Implement code changes on demand.** Assign Charlie to a GitHub issue or ask `@CharlieHelps, open a PR to fix this` — he will create a new branch, commit the changes, and open a pull request that addresses the issue. All commits and the PR will reference the relevant issue or task for traceability.
* **Brainstorm and plan solutions.** In an issue or PR comment, ask Charlie for an implementation plan (for example, `@CharlieHelps, how should we fix this?`). He’ll outline a step-by-step solution with code snippets, covering edge cases and validation.
* **Answer code questions in context.** Need an explanation of a piece of code or history? Mention Charlie in a comment (e.g. `@CharlieHelps, explain what this function does`) and he’ll pull context from the repository to provide a clear answer with references to the relevant files or commits.
* **Keep tasks and code in sync.** Charlie automatically links pull requests and commit messages to related issues (or Linear tickets if you use Linear). This ensures nothing falls through the cracks — every PR Charlie opens is tied to a tracking issue, and he checks that all requirements are met during his code review.
## Pull request reviews
Marking a PR as "Ready for review" or assigning the PR to `@CharlieHelps` will initiate a PR review.
* Inline review comments (on a specific diff line): Charlie only acts if the comment mentions `@CharlieHelps`. If the inline comments are part of a pending (unsubmitted) review, Charlie will not see them until you click 'Submit review'.
* Submitted multi-comment reviews: When you submit the review, Charlie will act if the review body or any of its inline comments mention `@CharlieHelps`.
* Request changes behavior:
* On PRs opened by Charlie: submitting a review with Request changes triggers Charlie to make edits even without a mention.
* On PRs opened by humans: Request changes does not trigger Charlie. Mention `@CharlieHelps`, request a review from `@CharlieHelps`, or assign the PR to `@CharlieHelps` instead.
Request changes is only actionable on PRs opened by Charlie.
## Working with Charlie in GitHub Issues
Charlie is fully integrated into the GitHub Issues workflow. You can assign work, request implementation plans, or ask technical questions—without leaving GitHub. Just mention `@CharlieHelps` in an issue or comment, and he’ll handle the rest.
### Opening a Pull Request from an Issue
Charlie can take an issue from idea to implementation:
* **Assign the issue to Charlie.** In the GitHub issue, assign @CharlieHelps as the assignee. Charlie will immediately start working on the issue, using the issue title and description as his primary specification.
* **Request a PR directly from an issue comment.** In any comment, mention Charlie with a clear instruction. For example: `@CharlieHelps, open a PR to fix this.` — Charlie will create a new branch, implement the fix, and open a pull request referencing the issue.
* **Link Sentry issues for deeper debugging.** If you have [Sentry](/integrations/sentry) connected, simply link a Sentry issue in your GitHub issue or PR description. Charlie will automatically pull in stack traces and error context from Sentry to better diagnose and resolve the problem.
- **Track progress in real time.** Charlie posts a status comment when he starts, and keeps it updated as he works.
### Communicating and Collaborating
Charlie supports a wide range of requests and questions inside issues:
* **Request a technical plan.** Ask Charlie for a detailed implementation plan or fix proposal `@CharlieHelps, outline a step-by-step plan to solve this issue.`
* **Research and brainstorm solutions.** Have Charlie gather external resources or best practices: ` @CharlieHelps, research approaches to this problem and include links to relevant documentation.`
- **Get instant answers.** Ask Charlie to explain code, dependencies, or past changes related to the issue: `@CharlieHelps, explain the impact of implementing this issue.`
- **Keep everything transparent.** Every action and response Charlie takes is posted directly in the issue, so your team stays in the loop.
Charlie’s responses in GitHub Issues are always context-aware—grounded in your codebase, changes history, and issue comments.
## Quick Setup
1. **Sign up and complete onboarding**\
Go to [Get Started](/get-started), create your account, and follow the onboarding steps.
2. **Invite Charlie to your repository**\
Add `@CharlieHelps` as a collaborator to your GitHub repo or organization.\
See [Inviting Charlie as a GitHub user](/get-started#inviting-charlie-as-a-github-user) for details.
## Troubleshooting
If something doesn't work as expected:
* **Charlie isn't responding on PRs** – Verify the **CharlieCreates** GitHub App is installed and enabled for the repository.
* **Can't mention @CharlieHelps** – Make sure `@CharlieHelps` has been invited to the repo (or is a member of the organization). If invites are delayed due to org policies, contact support.
* **Charlie can't push commits** – Ensure the app and/or user has write access to the target branch, or ask Charlie to open a PR from a new branch.
For more help, see the general Troubleshooting guide at [troubleshooting](/troubleshooting).
# Linear Integration
Source: https://docs.charlielabs.ai/integrations/linear
Linking Linear workspaces allows Charlie to open PRs, respond to comments, and more directly from your Linear.
## What Charlie can do
Once connected, Charlie will be able to:
* **Respond in-thread with answers and code.** Ask **@Charlie** follow-up questions or clarifications right on the issue.
* **Enrich the ticket with deeper context.** `@Charlie, enrich this issue` pulls stack traces, touched files, recent commits, and related PRs.
* **Draft a ready-made implementation plan.** `@Charlie, write an implementation plan` returns a step-by-step roadmap with code changes, tests, and rollout notes.
* **Open a pull-request from the issue.** Mention `@Charlie, open a PR for this` **or assign the issue to him**—he spins up a branch, pushes commits, and opens a PR that references the ticket.
* **Keep tracking in lockstep.** Commits, PRs, and issue states stay linked automatically, and Charlie surfaces missing requirements when reviewing the PR.
### Learn with Video Guides
Want to see Charlie in action with Linear? Visit our [learning center](https://www.charlielabs.ai/learn#linear) for comprehensive video guides demonstrating real-world examples of Charlie working with Linear integration.
## Quick Setup
Follow these steps to connect your Linear workspace with Charlie:
Navigate to [dashboard.charlielabs.ai/integrations](https://dashboard.charlielabs.ai/integrations) and log into your account.
If you have multiple GitHub organizations, you'll be prompted to select your organization before accessing the integrations page.
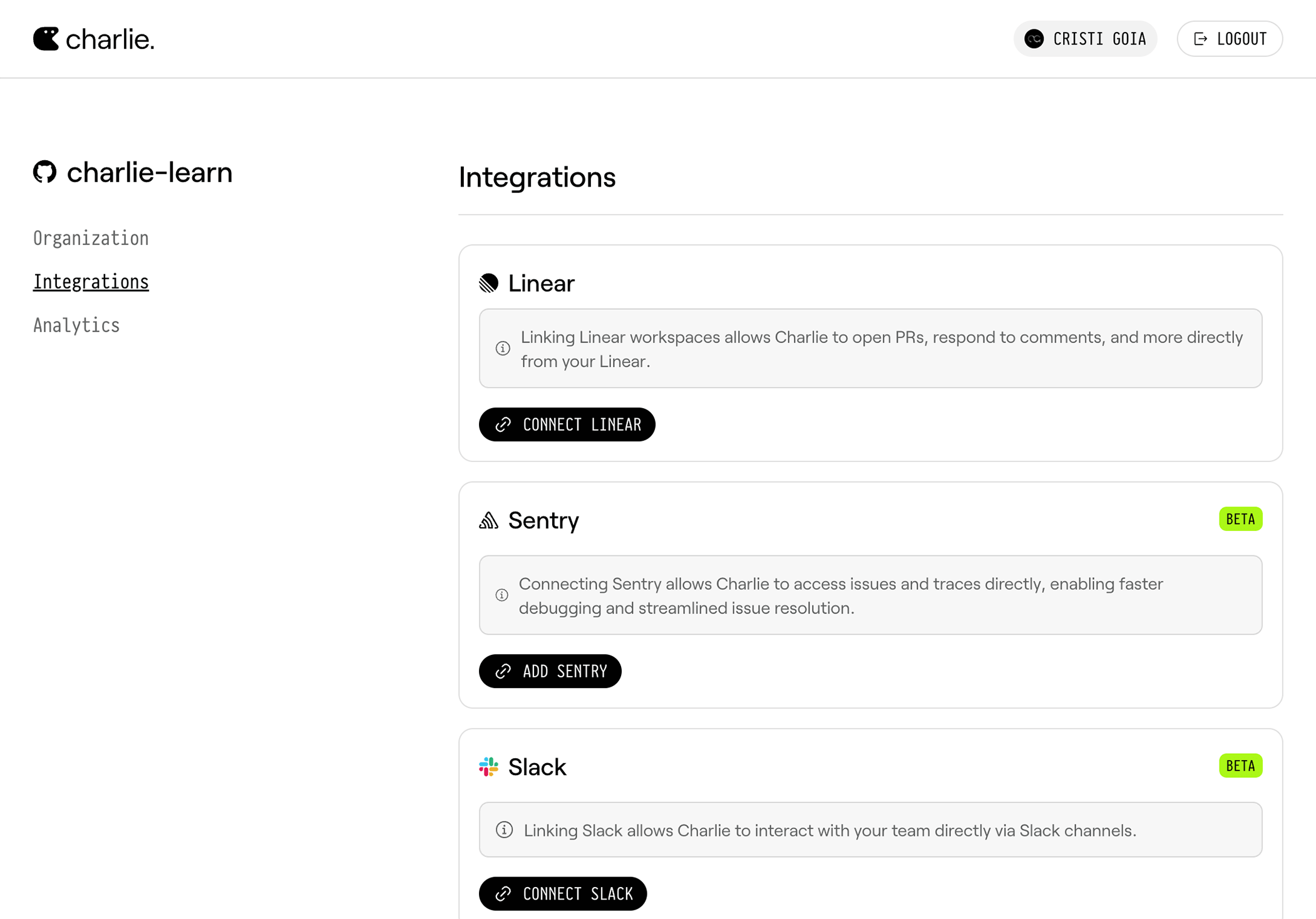
Click **Connect Linear** to initiate the integration process.
Follow the Linear OAuth connection flow to authorize Charlie to access your
Linear workspace.
After successfully linking your Linear workspace, you will be redirected back
to the Charlie dashboard.
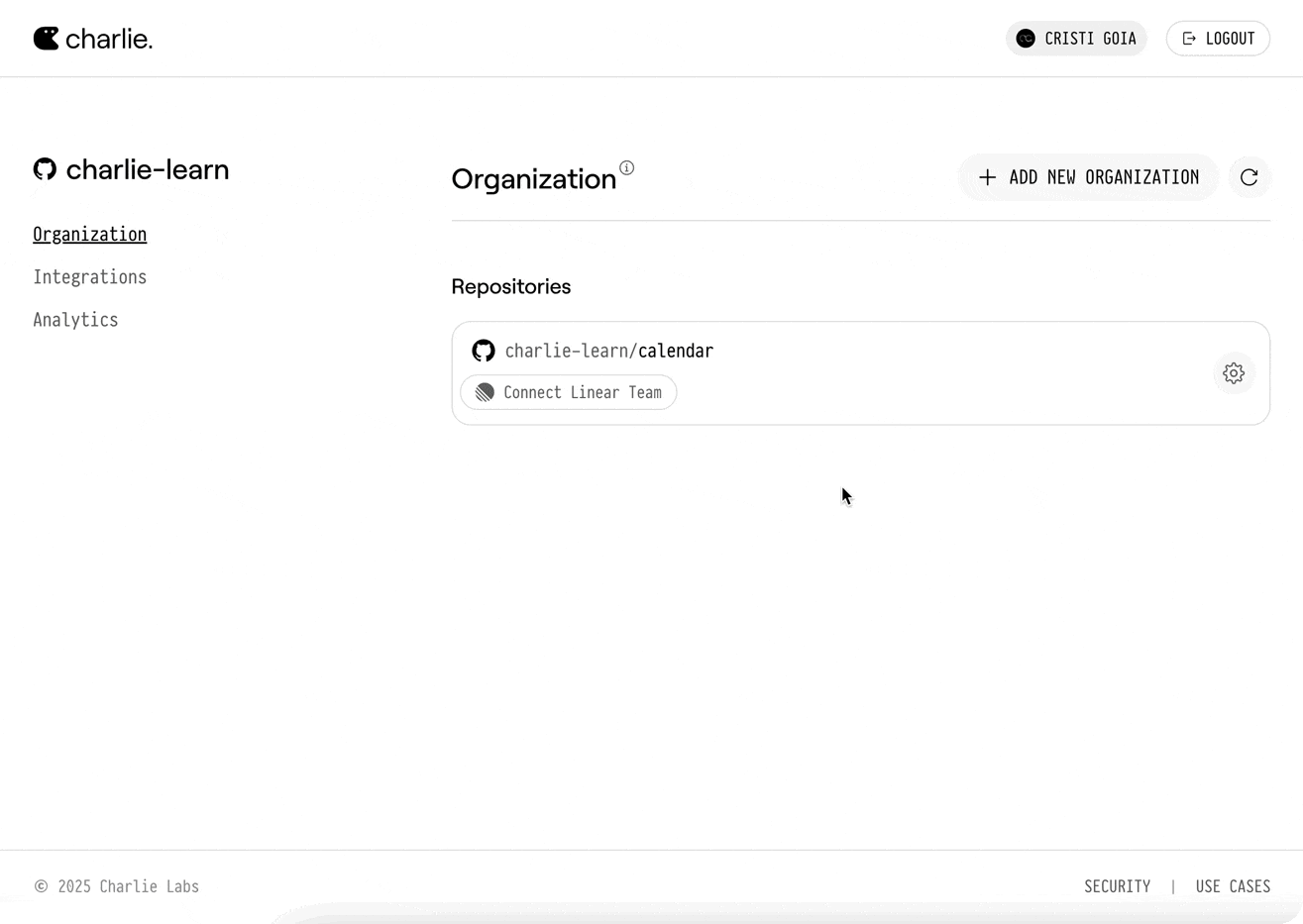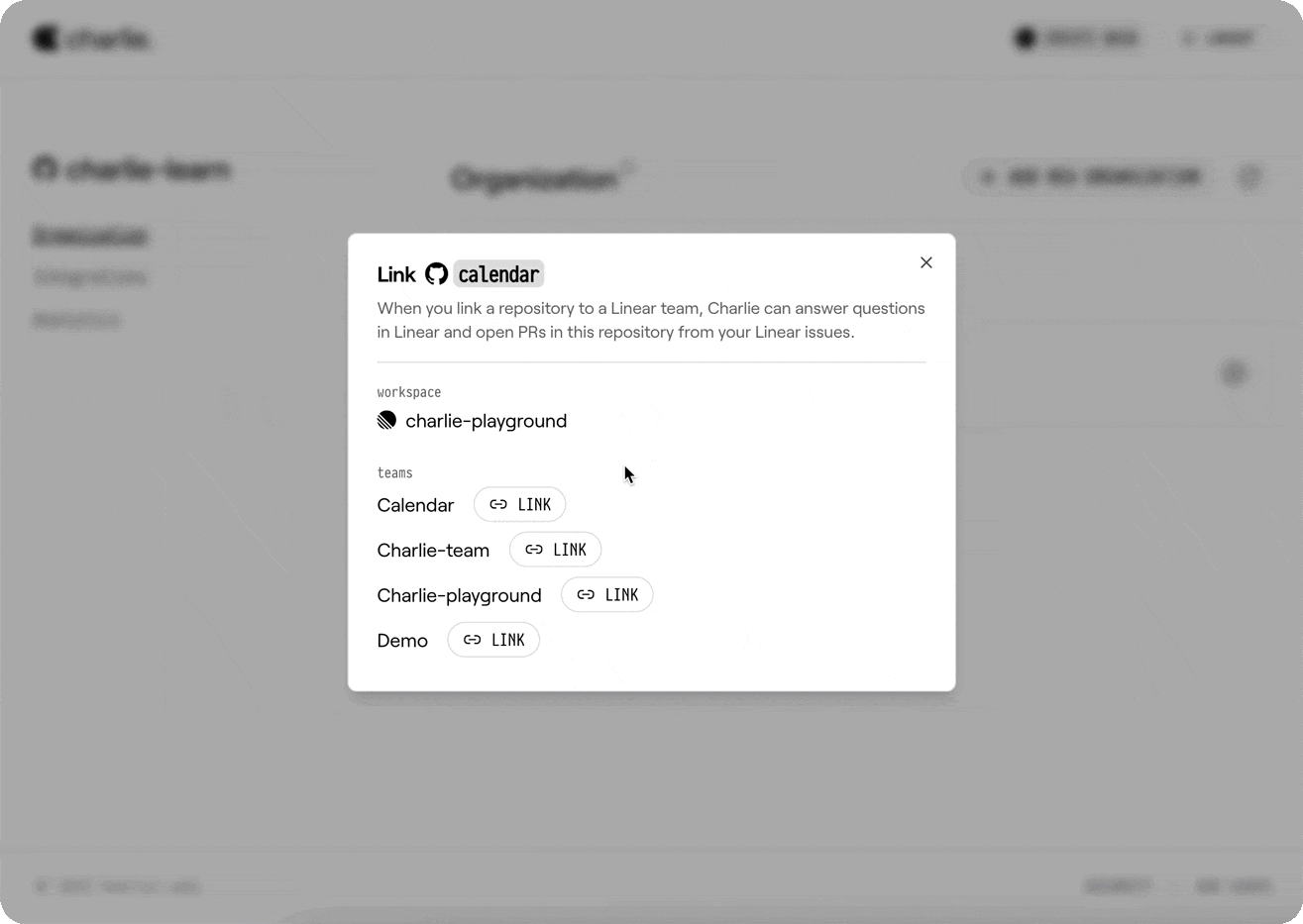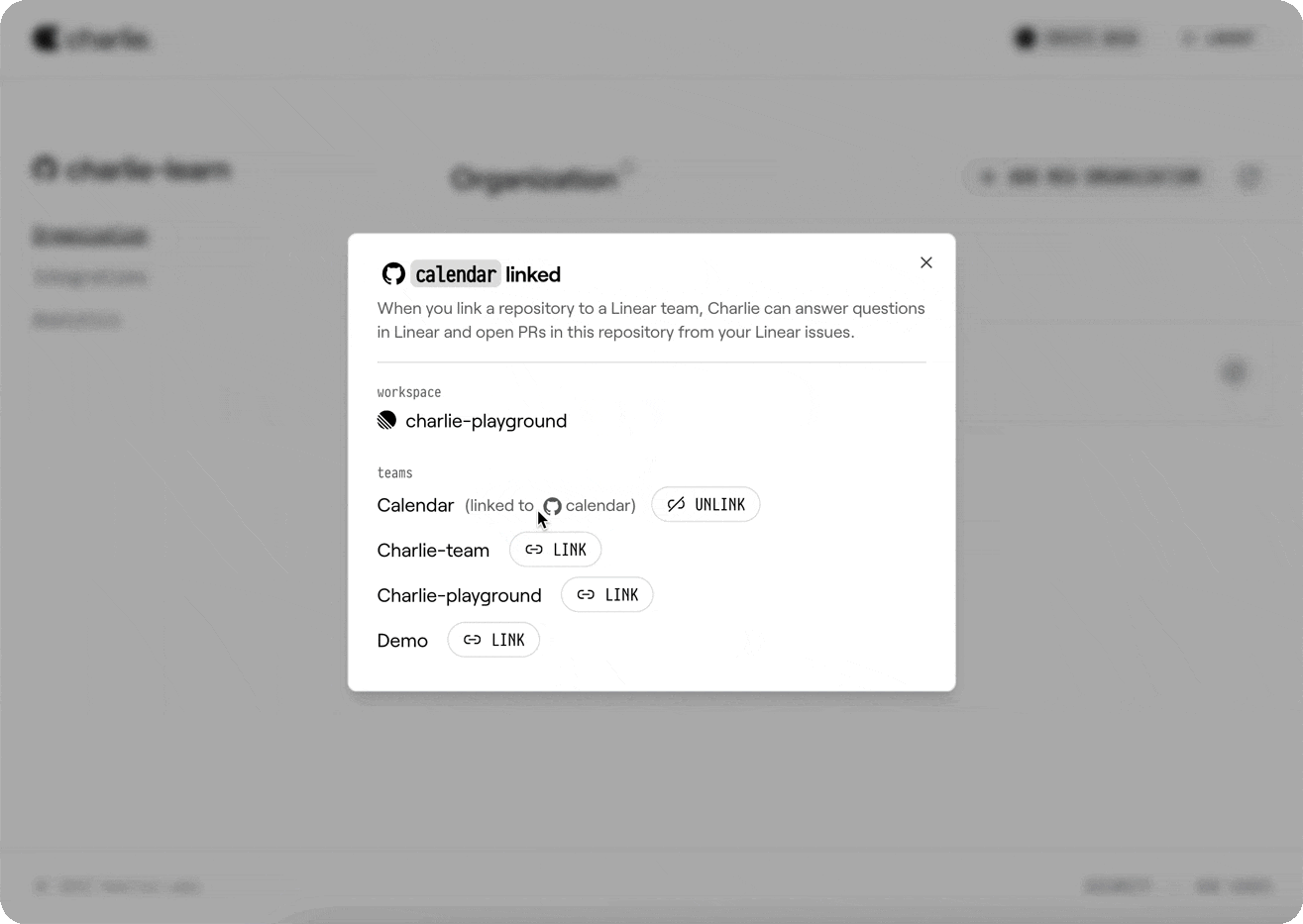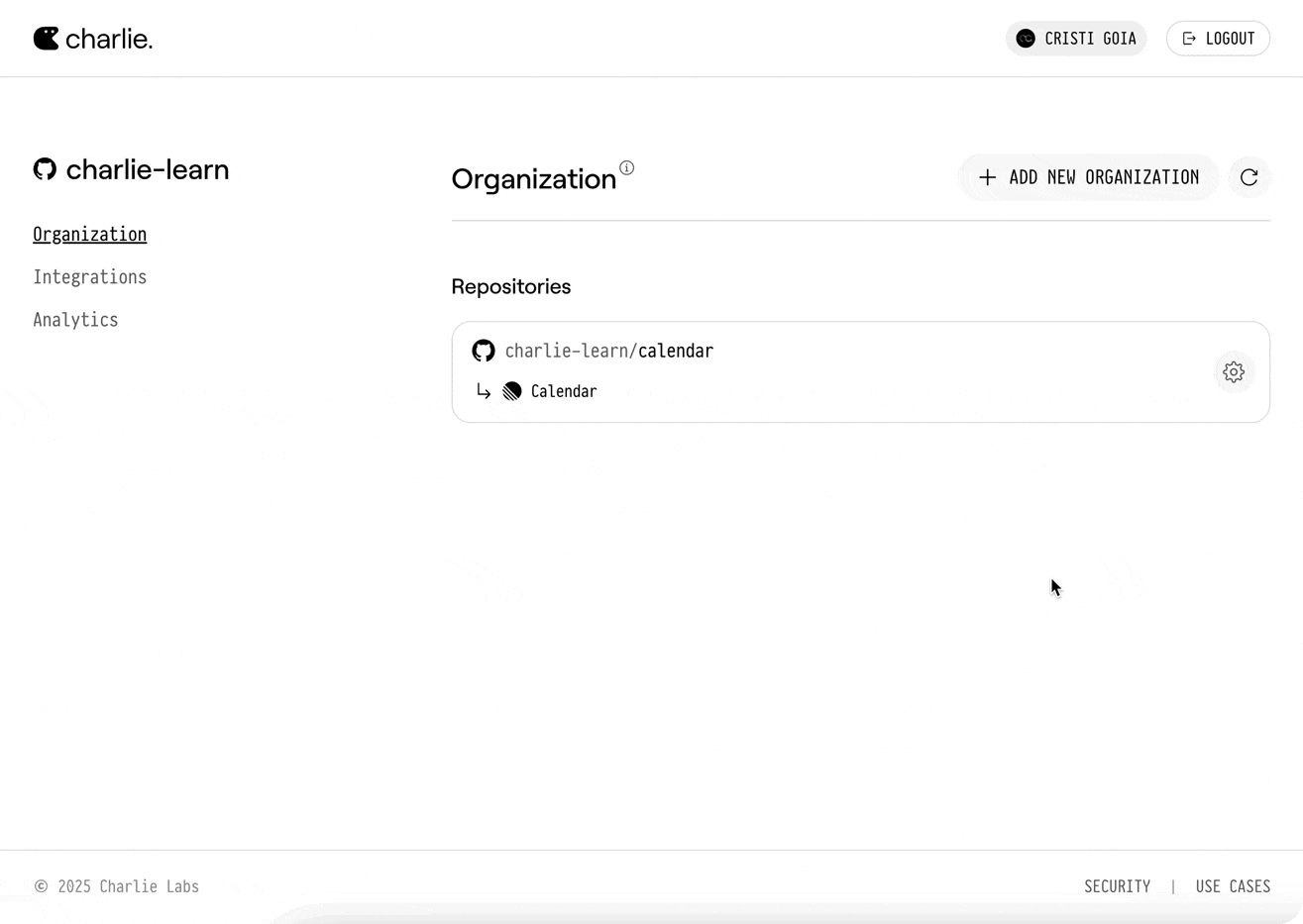
Go to your organization settings and select your desired repository to connect it with a Linear team.
# Sentry Integration
Source: https://docs.charlielabs.ai/integrations/sentry
Connecting Sentry allows Charlie to access issues and traces directly, enabling faster debugging and streamlined issue resolution.
## What Charlie can do
Charlie doesn’t just listen for Sentry webhooks—he actively digs into any Sentry trace he sees in Linear, GitHub, or Slack:
* **Inspect any Sentry trace in context.** Mention **@Charlie** on a Linear issue, GitHub issue/PR, or Slack message with a Sentry link and he fetches the stack trace, culprit commits, and frequency data.
* **Enrich the bug report automatically.** Charlie attaches that Sentry context back to the Linear ticket so the whole story sits in one place.
* **Generate a fix plan.** `@Charlie, draft a fix plan` outlines code edits, tests, and rollout steps ready for review.
* **Open a PR and ship the patch.** Approve the plan or say `@Charlie, open the PR` and he spins up a branch, commits the fix, and opens a PR linked to both Linear and Sentry.
## Quick Setup
Follow these steps to connect your Sentry organization with Charlie:
Navigate to [dashboard.charlielabs.ai/integrations](https://dashboard.charlielabs.ai/integrations) and log into your account.
If you have multiple GitHub organizations, you'll be prompted to select your organization before accessing the integrations page.
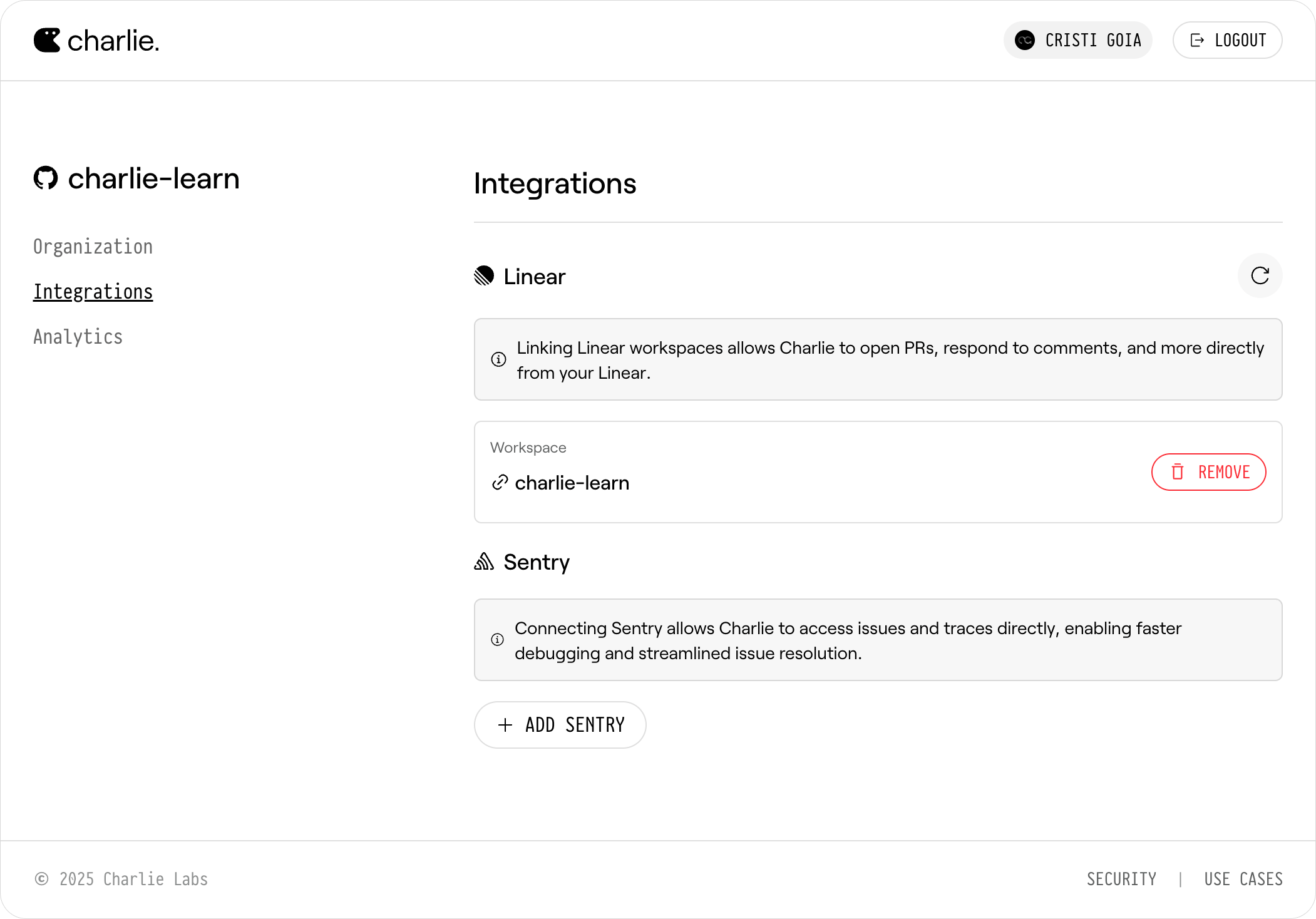
Click **Add Sentry** to open the integration popup. This will start a two-step process:
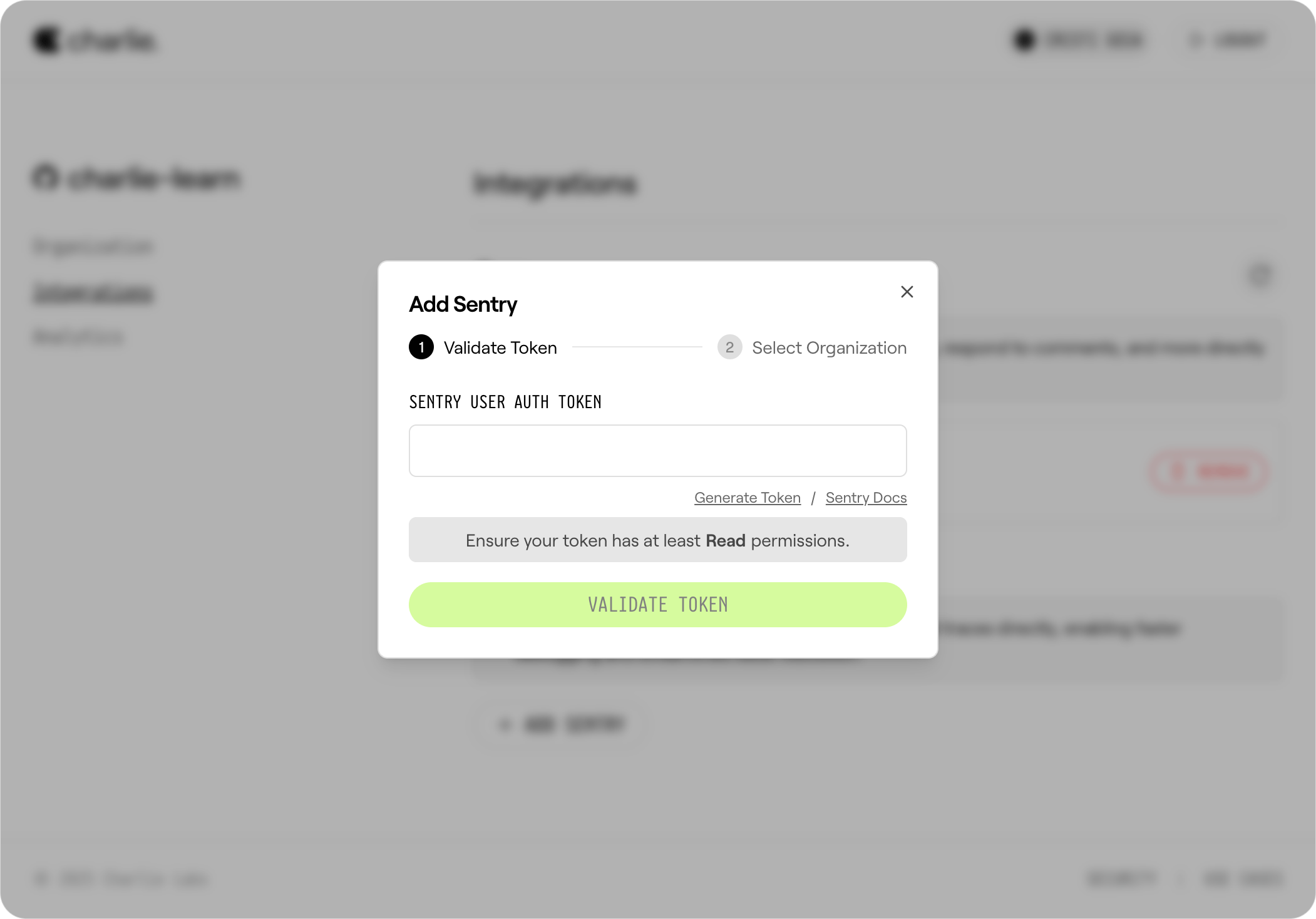
1. **Generate and Enter Token**: Get your Sentry User Auth Token from [https://sentry.io/settings/account/api/auth-tokens](https://sentry.io/settings/account/api/auth-tokens) (must have at least **Read** permissions).
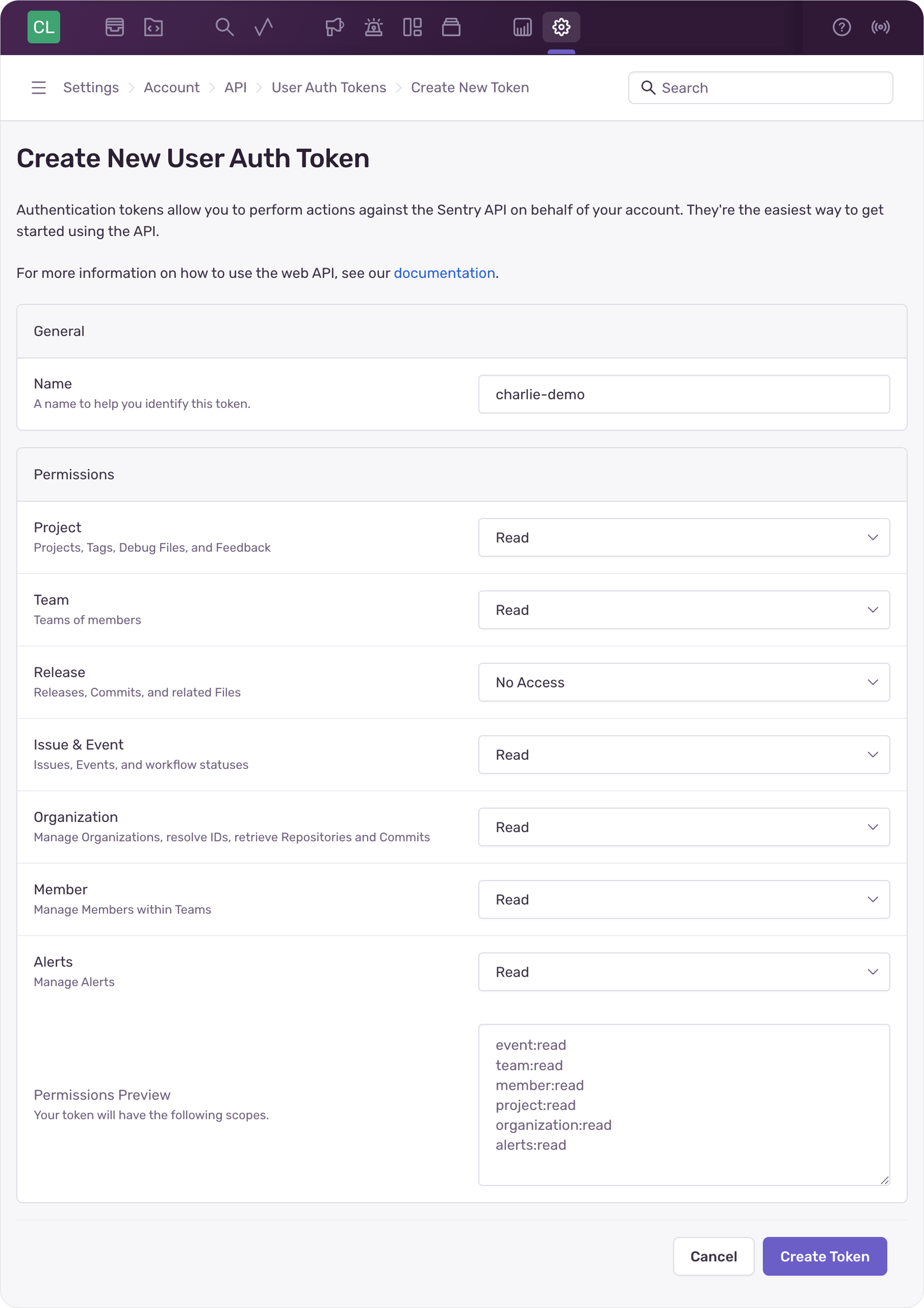
2. **Validate Token**: Click **Validate Token** - verify your token and retrieve your available Sentry organizations.
3. **Select Organization**: Choose your Sentry organization from the dropdown that appears after validation.
4. **Save**: Click **Save** to complete the setup.
Your Sentry organization is now connected to your GitHub organization.
## Troubleshooting
If you encounter issues during setup:
* **Token validation fails**: Ensure your token is valid and has at least **Read** permissions
* **No organizations appear**: Verify your token belongs to the correct Sentry account
* **Connection issues**: Check that your Sentry organization is accessible
# Slack Integration
Source: https://docs.charlielabs.ai/integrations/slack
Connecting Slack lets Charlie turn threads into actionable Linear tickets, surface git & Sentry context, and ship fixes—all without leaving the thread.
## What Charlie can do
With Slack connected, Charlie becomes a teammate in every channel:
* **Capture a bug or task as a Linear ticket.** Mention **@Charlie** (e.g., `@Charlie, create a Linear issue with this bug`) and he creates the ticket with the full conversation.
* **Pull rich context to understand the problem.** Ask `@Charlie, did we change anything before _X_ that caused this?` or drop a Sentry link—Charlie surfaces relevant commits, stack traces, and root-cause details.
* **Brainstorm and propose a fix plan.** `@Charlie, how should we fix this?` delivers approaches, edge-cases, and sample code blocks.
* **Open a PR straight from chat.** `@Charlie, open a PR to fix this` spins up a branch, commits the patch, and posts the GitHub PR back into the thread.
* **Summarise the discussion.** `@Charlie, summary please` condenses the thread into a crisp recap with action items and owners.
## Quick Setup
Follow these steps to connect your Slack workspace with Charlie:
Navigate to [dashboard.charlielabs.ai/integrations](https://dashboard.charlielabs.ai/integrations) and log in.
If you belong to multiple GitHub organizations, you'll be prompted to choose
the organization before accessing the integrations page.
Click **Connect Slack** to start the integration process.
Follow the Slack OAuth flow to authorize Charlie for your workspace.
After authorizing, you'll be redirected back to the Charlie dashboard.
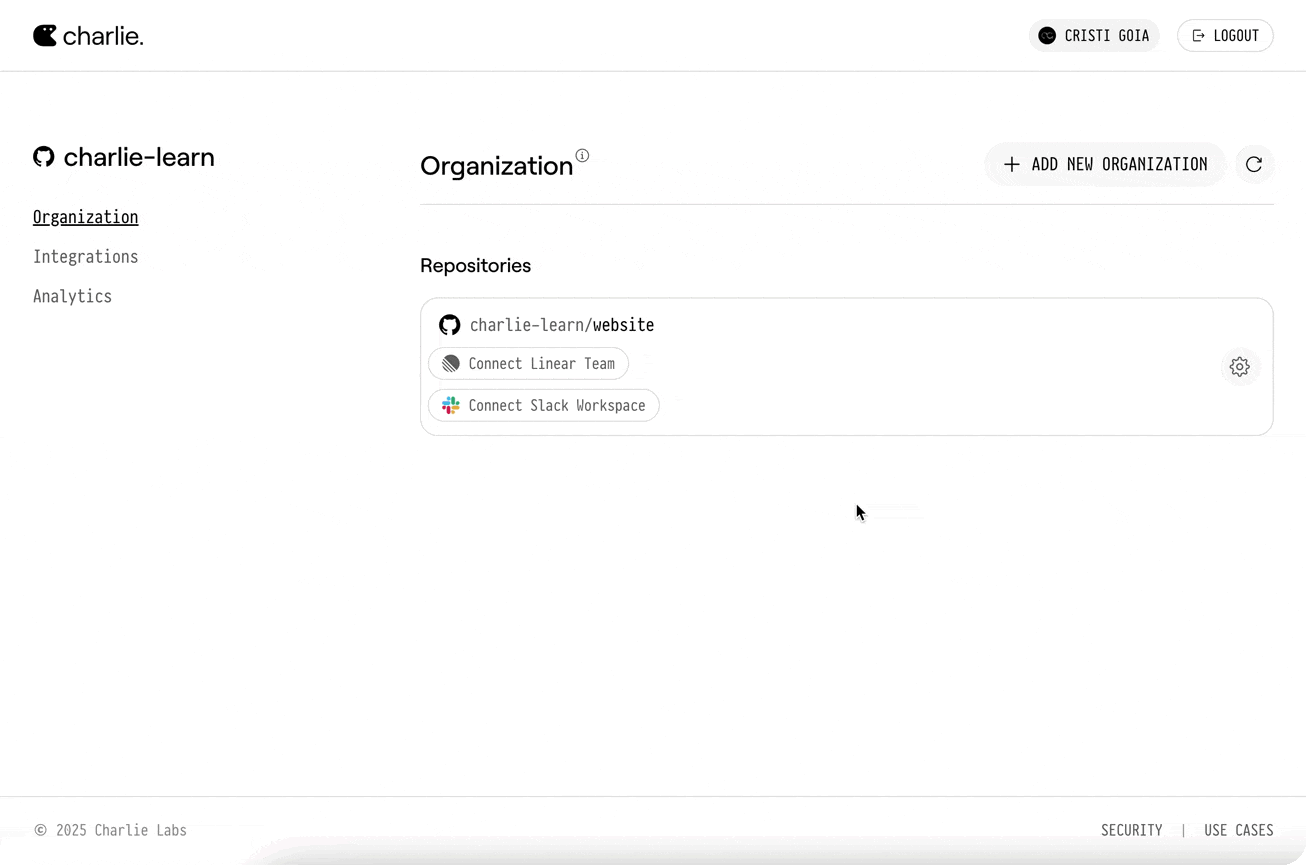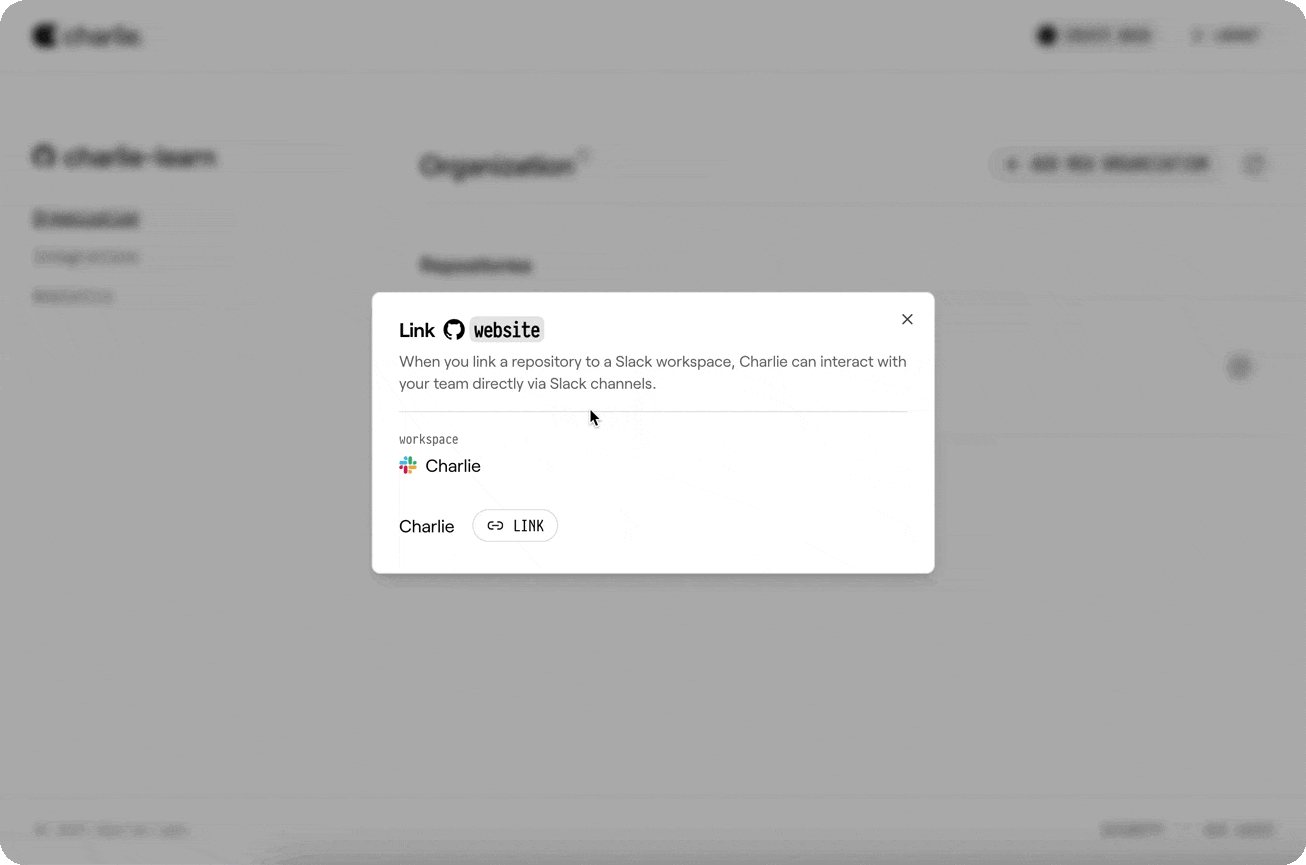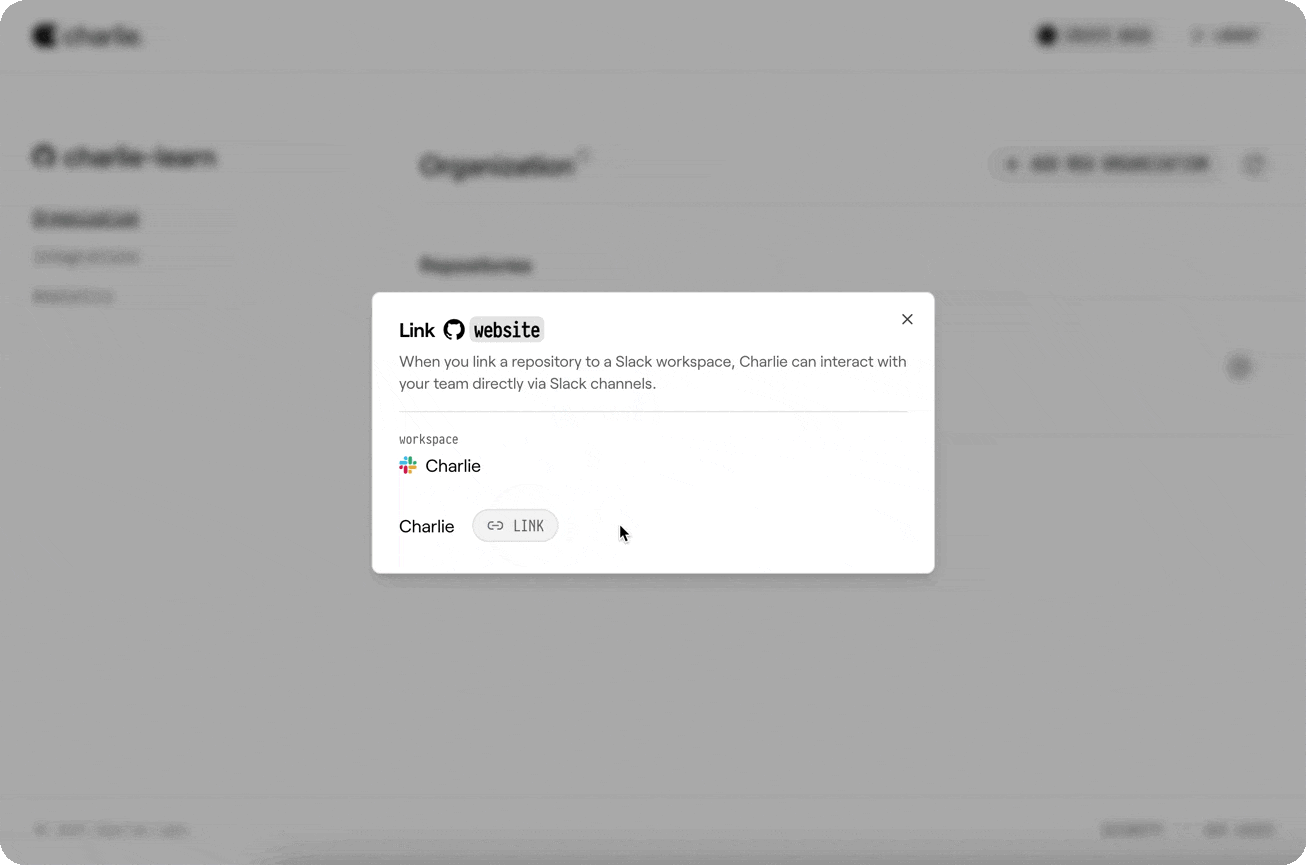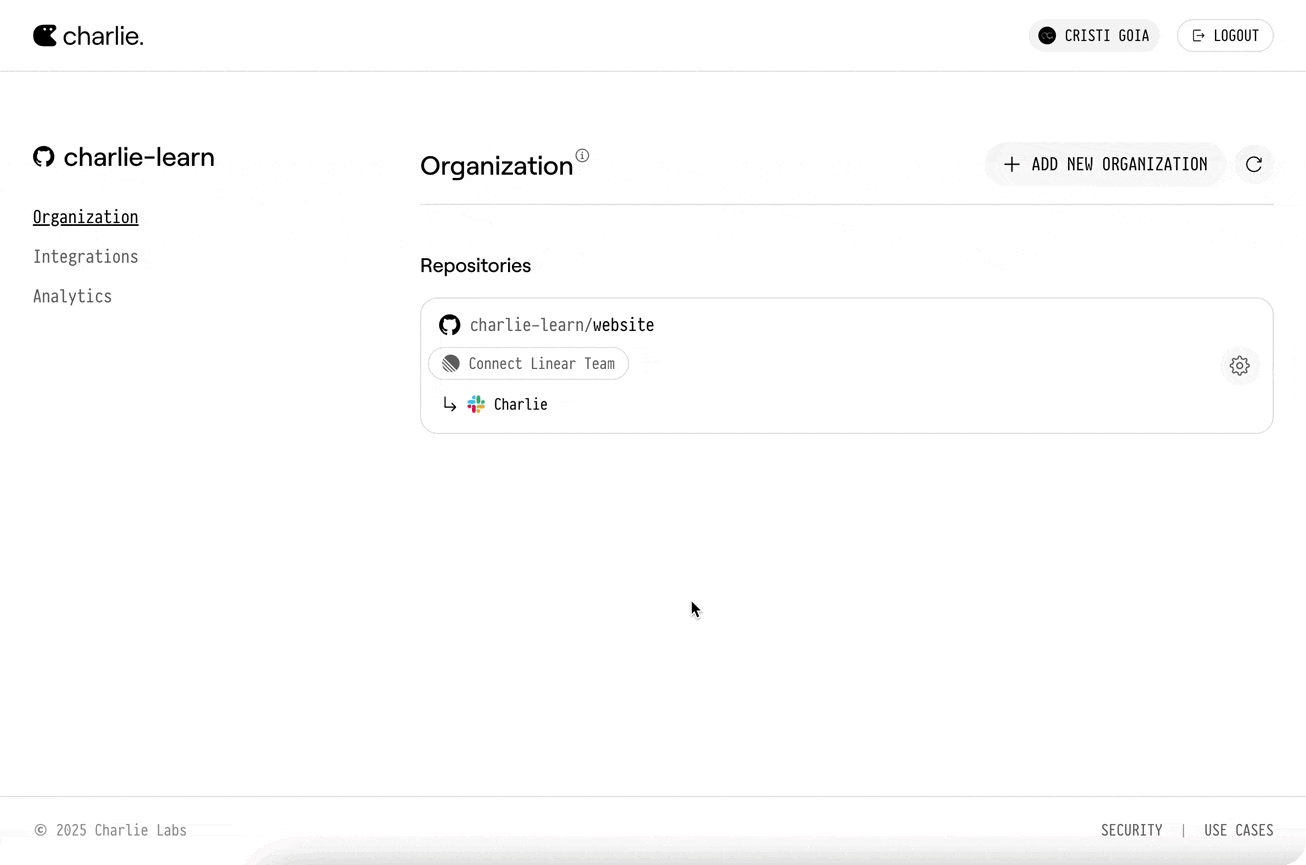
Go to your organization settings and select your desired repository to connect it with a Slack workspace.
# Vercel Integration
Source: https://docs.charlielabs.ai/integrations/vercel
Charlie ships via Vercel previews and production deploys out of the box - zero extra seats, tokens, or configuration.
## What Charlie can do
* **Automatic preview URLs** - Every branch Charlie opens spins up a Vercel preview so you can click, test, and iterate instantly.
* **Hands-free production deploys** - Merge the PR and Vercel ships to prod; Charlie never needs to join your Vercel team.
* **One seat, one flow** - Charlie acts only through GitHub, so your Vercel billing and permissions stay exactly as they are.
* **Tighter feedback loop** - Review the code, open the preview, ship the fix - all in one pass.
## Quick Setup
Good news - there is nothing to configure.
### Ensure the Vercel GitHub App is installed
If your repository already has the [Vercel GitHub App](https://github.com/apps/vercel) installed you are done - Charlie will automatically trigger builds and deployments whenever he pushes commits or opens a PR.
No API tokens, seats, or additional permissions required.
# Open Source
Source: https://docs.charlielabs.ai/open-source
How Charlie participates in public repositories on GitHub (general availability), including exact invocation & skip rules.
* Available for all customers on public GitHub repositories
* Charlie never writes to forks or unapproved public repos
* Maintainers (write/admin) must initiate – outside contributors cannot trigger runs alone
* Explicit mention or review request drives most interactions
* Non‑Charlie bots & fork-based PRs are ignored
This document explains how Charlie behaves on **public (open source) GitHub repositories** so maintainers know when Charlie will and will not respond.
***
## Scope & Access Model
Charlie’s open source support is now available to all customers. Access is governed by the authorization and safety rules below. Access is tightly controlled to prevent abuse (and spending of customers' Charlie credits by unauthorized users).
### Supported Repositories
| Repo visibility | Fork origin | Result |
| --------------- | ----------- | ------------------------- |
| Private | N/A | Standard product behavior |
| Public | Same repo | Open source rules (below) |
| Public | Fork PR | Ignored |
**Fork PRs are always ignored.** To have Charlie participate, push your branch to the primary (upstream) repository.
***
## Authorization Requirements
For Charlie to respond in a public repository:
* **Sender must not be a non‑Charlie bot.** (`dependabot`, `github-actions`, etc. are skipped.)
* **Sender must be an authorized human: a repository *owner*, or an *organization member* or a non-member with `write` or `admin` permissions.**
* **Event must not originate from a forked head repository.** (Mitigates supply‑chain / fork poisoning vectors.)
If any requirement fails, the event is silently ignored.
***
## Invocation Rules (When Charlie Will Respond)
Charlie responds only to the actions below after the authorization checks pass.
### Direct Interaction Triggers
* **Issue or PR comment**
* Conditions: Comment *mentions Charlie* (`@CharlieHelps`) AND author is an authorized human.
* Action: Charlie replies in the thread. If you forget the mention, nothing happens.
* **Standalone PR review comment** (not part of a pending multi-comment review)
* Conditions: Comment mentions Charlie AND author is an authorized human.
* Action: Charlie replies.
* **Submitted multi-comment PR review**
* Conditions (any of):
* The review body *or any individual review comment* mentions Charlie, OR
* Charlie authored the PR **and** the review state is `changes_requested`.
AND reviewer is an authorized human.
* Action: Charlie replies in the PR conversation.
* **Issue assigned to Charlie**
* Conditions: Charlie is in the assignee list, the issue is open, AND the assignment was made by an authorized human.
* Action: Charlie responds (no explicit mention required).
### Indirect / Automation Triggers (No immediate reply)
* **PR opened**
* If the PR is *not* a draft **or** Charlie authored it, and it was opened by an authorized human, Charlie automatically requests itself as a reviewer (configurable – see Section 4). This does **not** produce an immediate reply; the later review request event, a mention, or a PR assignment will.
* **PR marked ready for review**
* If the PR transitions from draft and automation is enabled, and the transition was performed by an authorized human, Charlie requests a review.
* **Review explicitly requested**
* If Charlie is the requested reviewer and the PR is open, Charlie responds (request made by an authorized human).
***
## Automatic PR Review Request Behavior
By default, Charlie will auto‑request itself as a reviewer when:
* A non-draft PR is opened by an authorized human, or
* A draft PR is marked ready for review by an authorized human.
This behavior is controlled by the repository configuration key: `beta.automaticallyReviewPullRequests` (default `true`). If disabled, maintainers must manually request a review, mention Charlie, or assign the PR to Charlie to start work.
***
## Skip Rules (When Charlie Will NOT Respond)
Charlie intentionally **ignores** the scenarios below. Most produce *no visible indication*; this is expected.
| Category | Example Scenario | Reason |
| ------------- | -------------------------------------------------------------------------- | ------------------------------------------------------- |
| Authorization | Comment by external contributor | Sender lacks required write/admin permissions |
| Fork Safety | PR opened from a fork | Fork PRs are ignored |
| Bot Noise | Dependabot (or other third‑party bot) mentions Charlie | Non‑Charlie bot senders ignored |
| Mentions | Comment lacks `@CharlieHelps` | Requires explicit mention in that context |
| Self‑loop | Charlie authored the triggering review | Already Charlie's action; no extra response |
| Review State | PR review on Charlie-authored PR without mention & not `changes_requested` | No explicit signal to act |
| Permissions | Review submitted by actor with only read access | Read-only reviewers cannot trigger responses |
| Issue Body | Issue opened with `@CharlieHelps` in body | Initial body mention ignored; comment or assign instead |
***
## Practical Examples
Add Charlie as a reviewer *or* comment: @CharlieHelps please review the concurrency changes in src/worker/pool.ts
Comment in the issue: @CharlieHelps draft an implementation plan covering validation & migration steps
Opening a PR from a personal fork will be ignored until you push the branch to the main repo.
A Dependabot comment mentioning Charlie is skipped; a maintainer must follow up.
***
## FAQ
**Why ignore forked PRs?**\
Minimizes risk of untrusted code influencing automated reasoning before a maintainer reviews & deliberately brings it into the main repo.
**Can external contributors still get help?**\
Yes—ask a maintainer to mention Charlie, request a review, or assign the PR to Charlie after validating the contribution direction.
**Will Charlie ever proactively comment without a mention?**\
Only with a mention or a PR assignment by an authorized human.
**How do I disable auto review requests?**\
Set `beta.automaticallyReviewPullRequests` to `false` in your configuration (UI surface not yet exposed for open source repos).
***
***
Questions? Reach out at [hello@charlielabs.ai](mailto:hello@charlielabs.ai).
# Security
Source: https://docs.charlielabs.ai/security/index
**Last updated: May 20th, 2025**
Keeping your source code and developer environment secure is important to us. This page outlines how we approach security for Charlie. For any security-related questions or to submit potential vulnerabilities, feel free to contact us at [hello@charlielabs.ai](mailto:hello@charlielabs.ai).
***
## Certifications and Third-Party Assessments
We have obtained our **SOC 2 Type I** certification, and our **SOC 2 Type II** assessment is currently in progress. See our [Trust Center](https://trust.charlielabs.ai) for more details.
***
## Terminology
* `Sees your code` – Has an entire copy of the repository.
* `Sees code snippets` – Access is limited to fragments (e.g., a pull-request diff) of your code.
* `Does not see your code` – Has no access to your repository or code snippets.
***
## Providers
* [**GCP**](https://cloud.google.com/security) – `Sees code snippets` – We use GCP for our primary infrastructure and secret management.
* [**Sentry**](https://sentry.io/security/) – `Sees code snippets` – We use Sentry for error monitoring and logging.
* [**OpenAI**](https://openai.com/security-and-privacy/) – `Sees code snippets` – Used for inference.
* [**Anthropic**](https://trust.anthropic.com/) – `Sees code snippets` – Used for inference.
* [**Runloop**](https://trust.oneleet.com/runloop) – `Sees your code` – Provides isolated and secure VM environments for Charlie.
* [**SerpAPI**](https://serpapi.com/security) – `Does not see your code` – Used to search the internet.
* *Optional*: [**Slack**](https://slack.com/security-practices) – `Sees code snippets` – If you connect your Slack workspace, Charlie may respond to messages with code snippets.
* *Optional*: [**Linear**](https://linear.app/security) – `Sees code snippets` – If you connect your Linear workspace, Charlie may respond to comments with code snippets.
***
## Data Security
* We do **not** use any open-source hosting/training or DeepSeek AI models.
* Charlie exclusively uses **OpenAI, Anthropic, and Google** as AI service providers.
***
## Access Control
* The GitHub user account `@CharlieHelps` has the access you granted through GitHub.
* The GitHub App `CharlieCreates` has the access you granted through GitHub.
* `@CharlieHelps` uses multi-factor authentication (MFA).
* All interactions with `@CharlieHelps` are handled exclusively with encrypted private GitHub tokens.
***
## Infrastructure
* We use **Google Cloud Platform (GCP)** for our primary infrastructure.
* We enforce multi-factor authentication for all GCP accounts.
* We use **Terraform** for infrastructure-as-code to track and review changes.
* We assign infrastructure access on a least-privilege basis.
* We use both network-level controls and secrets to restrict resource access.
***
## How We Use Your Data
* We use your data to **evaluate Charlie’s performance** (e.g., diagnosing failures, measuring feature usage).
* We do **not** sell your data to third parties.
* We do **not** use your data for any purpose other than providing you with Charlie.
* We store the minimum data necessary to achieve our business goals.
* Your **source code** is **never** used for training or fine-tuning any machine-learning or language models.
* Aggregated **feedback signals** you provide (e.g., thumbs-up/down reactions, comments) **may** be used to fine-tune models and improve product quality.
***
## Attribution and Compliance
* **You own all of the code** generated by Charlie, to the extent permitted by law.
* Charlie uses **OpenAI, Anthropic, and Google** AI models to generate code, and you assume all risks that come with AI-generated code.
***
## Account Deletion
You can delete your account by contacting us at [hello@charlielabs.ai](mailto:hello@charlielabs.ai).
# Initial setup & installation
Source: https://docs.charlielabs.ai/setup
Install the GitHub App, invite @CharlieHelps, optionally connect Slack/Linear/Sentry, add env vars, and activate your subscription.
## Overview
This guide covers the minimum steps to enable Charlie in your GitHub organization. Slack and Linear are optional and can be connected anytime from the dashboard.
## Prerequisites
* GitHub organization admin permissions (to install the app on repos)
* Access to a Linear workspace and/or a Slack workspace (optional)
* Ability to add repository environment variables for private builds/tests (optional)
- Go to [https://dashboard.charlielabs.ai/signup](https://dashboard.charlielabs.ai/signup) and sign up. You’ll land on onboarding.
* Click “Install on GitHub” and install the GitHub App on the repositories where you want Charlie to help.
* App slug: `charliecreates` (direct link: [https://github.com/apps/charliecreates/installations/select\_target](https://github.com/apps/charliecreates/installations/select_target))
* You can choose “all repositories” or a subset; you can change this later.
* After installation, you’ll be returned to the dashboard to finish setup.
Open Manage → Subscription for your organization and pick a plan. You’ll be sent to Stripe checkout.
After payment, you’ll land on “Subscription activated” and Charlie becomes active for the org.
Invite the GitHub user account `@CharlieHelps` to your org (recommended) or per‑repo so teammates can request reviews from and mention Charlie directly in GitHub.
* Add to organization (recommended)
1. Open [https://github.com/orgs/YOUR\_ORG/people](https://github.com/orgs/YOUR_ORG/people)
2. Click “Invite member” and search for `CharlieHelps`
3. Invite `@CharlieHelps` as a member
4. During the invite (or after acceptance), grant repository access to the target repos with the `Triage` role
* Add to a single repository
1. Open [https://github.com/YOUR\_ORG/YOUR\_REPO/settings/access](https://github.com/YOUR_ORG/YOUR_REPO/settings/access)
2. Click “Add people” and search for `CharlieHelps`
3. Set the repository role to `Triage` and confirm the invite
This is separate from the GitHub App installation. The App provides repo access; the `@CharlieHelps` user enables mentions and PR review requests.
You can connect Linear during onboarding or later at Manage → Integrations.
* To connect: the dashboard redirects you to Linear OAuth, then back to the dashboard.
* After connecting, link a repository to a Linear team (Onboarding → “Link Repository & Team”, or Manage → Integrations → Linear):
* Pick the GitHub repository
* Pick the Linear team
* Click “Complete Linking”
Linking ensures Charlie uses the intended repo/team without guessing.
You can connect Slack during onboarding or later at Manage → Integrations.
* To connect: the dashboard redirects you to Slack OAuth, then back to the dashboard.
* After connecting, link a repository to a Slack workspace (Onboarding → “Connect Slack”, or Manage → Integrations → Slack):
* Pick the GitHub repository
* Pick the Slack workspace
* Click “Complete Linking”
Let Charlie reference your error data during runs. You can connect Sentry anytime from Manage → Integrations.
* In Sentry, create a user token with API access.
* In the dashboard, go to Manage → Integrations → Sentry and paste the token; choose the Sentry organization to link.
* After connecting, you can ask Charlie to “check Sentry for this issue” in Slack/Linear or a PR thread, and Charlie will pull incidents and traces as context.
If your repo needs secrets for building, linting, or tests (used by Charlie’s devbox when running your `checkCommands`), add them per‑repo:
* Manage → Organization → select a repository → Environment variables
* Add key/value pairs. Values are encrypted and hidden in the UI after save.
* Open or mark a pull request “Ready for review”. By default, Charlie automatically reviews PRs when opened or marked ready.
* You can also request a review from `@CharlieHelps` or mention `@CharlieHelps` in a PR/issue comment to ask for help.
### Behavior reference
* Automatic PR reviews are controlled by your repository’s `.charlie/config.yml` (`beta.automaticallyReviewPullRequests`, default: true). You can add this later if you want to customize behavior. See the [Configuration & advanced setup](/config-advanced) page.
***
That’s it. Revisit Manage → Integrations anytime to connect/disconnect Linear, Slack, or Sentry, and Manage → Billing & Usage to view credit usage.
## First‑run tips
* Screenshots and images are supported. When helpful, include a short caption or annotation and link related files for context.
* Write a one‑sentence PR description with intent and non‑goals. Example: “Extract `UserCard` to its own file—no behavior change.”
* Call out pure refactors or JS→TS conversions so reviews focus on the diff that matters.
* In Slack/Linear, if the context is long, ask Charlie to briefly summarize the thread, then state the task.
# Troubleshooting
Source: https://docs.charlielabs.ai/troubleshooting
Fix common issues when setting up or using Charlie
Below are solutions to the most frequent hurdles teams run into when getting Charlie up and running. If your question isn't answered here, reach out on our shared Slack channel or email [support@charlielabs.ai](mailto:support@charlielabs.ai).
When Charlie fails, he will tell you what to do next. Usually, he asks you to reply by mentioning him and saying `please continue`.
If Charlie fails multiple times and your account is properly set up, please contact support.
Charlie must be invited to your Linear **workspace *and* team** before he can comment or be assigned issues.
**Fix**
1. In Linear, go to **Settings → Teams → (choose your team) → Members**.
2. Click **Invite member** → search for **Charlie ([charlie@charlielabs.ai](mailto:charlie@charlielabs.ai))**.
3. Give him the **Contributor** role (minimum).
4. Re-run the action; Charlie should now show up in assignee menus.
* Verify the *CharlieCreates* GitHub App is **Installed & Enabled** for the repository.
* Review GitHub’s official guide on managing installed apps: [GitHub’s guide to reviewing and modifying installed apps](https://docs.github.com/en/apps/using-github-apps/reviewing-and-modifying-installed-github-apps)
* Make sure CharlieHelps has been invited to the repo (or is a member of the organization).
* "Read" permissions are all the helper account needs.
* If the invite hasn't been accepted in 15 minutes, reach out to support. This is typically caused by organizations having strict secrurity policies around invites.
Charlie reports **“Committed changes to branch *xyz*”** in the PR timeline, yet no new commits show up on GitHub. The most common culprit is a **local pre-commit hook** that fails after the commit is created.
* a script relying on Bash-specific features while being invoked with plain **sh**, or
* a Windows-style line ending in the shebang line (e.g. `#!/bin/sh` saved with `CRLF`).
When the hook exits non-zero Git aborts the commit, so nothing is pushed.
**Fix**
* Ensure every script is POSIX compliant.
* Ask Charlie to scan the repository for non-POSIX compliant scripts or script templates and open a PR to update them to POSIX compliance.
There is **no stop button (yet)**—once a Charlie run starts it will keep
running until it either **completes** or **errors out**.
#### If you need to get back to a clean slate
* **Wait** until Charlie finishes.
* Then **reset, revert, or manually edit** the commits he pushed.
* **Ask Charlie**—leave a comment on the pull request requesting that he
reset, revert, or edit the commits for you.
#### Alternative workaround
* **Create a new branch** from the current `HEAD` and continue your work
there while Charlie completes its run on the original branch.
#### Heads-up on force pushes
Charlie pushes with `git push --force-with-lease`. If you manually
force-push over his work before the run ends, Charlie’s next push will
overwrite your changes.
